FIGURE A. Pattern of word choice in Le Monde
README--FIRST 2003
LEXICAL ACCESSIBILITY (LEX)
Introduction.
New concepts and valid, precise tools for their measurement
have triggered major changes in science. Our conceptions of ‘size’ and ‘scale’ in the natural world were transformed by the development of the telescope and microscope. The development of such tools continues to be valued in science: the 1999 Nobel prize in chemistry was awarded to an investigator for work on measuring and describing chemical reactions at the molecular level. That work has produced a new field--femtochemistry.
Given the respect for and experience with such tools in science, it is puzzling that tools which meet those standards: validity, reliability, robustness, stability and precision, are so uncommon in the area which is most distinctly human: our use of language in spoken, written and broadcast forms. Like the air we breathe, texts are both ubiquitous and essential to our laws, social contracts, the production and distribution of news, and to our intellectual lives. The most extensive development of text analyses are the variants on 'content analysis', whose history included centuries of religious and literary text analyses and recent applications in the human sciences -- all carried without computers. Few of those tools meet those five standards for measurement. Prominent features of all natural texts remain unmeasured, scientifically.
LEX. The measurement and validation of a text’s relative ‘accessibility’ to its audience has been the center of a 23 year line of research, much of it included the CORNELLCORPUS2000. From the WEB at . A text’s ‘accessibility’ is a principal component of what makes text’s understandable. LEX is estimated by a statistic whose values range from -123 to +85. TABLE 1 describes the spectrum of LEX scores in a wide variety of natural texts. This Table serves as one Reference Source for interpreting LEX scores.
TABLE 1
THE SPECTRUM OF NATURAL TEXTS AND THE LEVELS AT WHICH THEY WERE PITCHED
Text source Date/N LEX MeanU*
Nature--article on transhydrogenase 1960 58.6 44
Cell--research articles 1989 41.1 91
Nature--main research articles 1990 34.7 107
J. Amer. Chem. Assoc.--articles 1990 33.3 94
New Engl. J. of Medicine--articles 1990 27.0 126
Science--main research articles 1990 26.9 120
Scientific American--articles 1991 14.3 158
Watson-Crick DNA model in Nature 1958 11.1 164
New Scientist--articles 1990 7.2 191
Popular Science--articles 1994 4.6 197
Time magazine--articles 1994 1.6 211
Economist--articles 1990 0.9 210
NEWSPAPERS: English-language, Intl. N=61 0.0 216
Nature--research articles 1900 -0.5 226
National Geographic--articles 1984 -0.6 199
Discover--articles 1990 -2.6 229
The Times (London) 1791 -3.0 233
New Yorker--articles 1994 -3.9 231
Colonial American newspapers (3) 1720-1730s -4.3 236
Smithsonian--articles 1988 -9.1 264
Will. Shakespeare's plays(w/o archaics) N= 37 -12.0 292
Adult books--fiction, USA N= 34 -15.8 282
Comicbooks--GB & USA N= 37 -23.7 318
Child books, read at ages 10-14, GB N=261 -24.3 312
TV--cartoon shows N= 26 -28.6 339
TV--primetime shows N= 44 -36.4 371
Pre-school books read to children N= 31 -37.0 360
Adult to adult conversations N= 68 -37.5 375
Legal wiretaps on a cocaine dealer 1990 -42.2 387
Winnie the Pooh--Milne -43.3 381
Mothers' talk to children, age 5 N= 32 -45.8 394
Dairy farmer talking to his cows -56.0 520
Pre-Primer--Houghton Mifflin 1956 -80.5 640
* U = Frequency per million tokens (Carroll, Davies & Richman, 1971)
LEX scores are derived from a comprehensive analysis of a text’s use of the English lexicon, estimated to contain over 600,000 word-types (Carroll, 1971). There are two principal LEX measures: LEX(c) for the text’s use of ‘content’ or ‘open class’ word-types (52-55 percent of all the text’s words); and the second LEX(g)for the text’s use of all the principal function or grammatical word types in English (45 to 48 % of the words used). The absence of the suffix indicated LEX refers to the content terms of the text–-the words which carrying the bulk of the substance in this text. LEX scores have a sign and numeric value. Negative LEX scores describe texts whose word choice is skewed toward the most common words in English. Positive LEX scores describe texts whose word choice is skewed toward rare terms. The numerical value of a LEX score describes the extent of that skew.
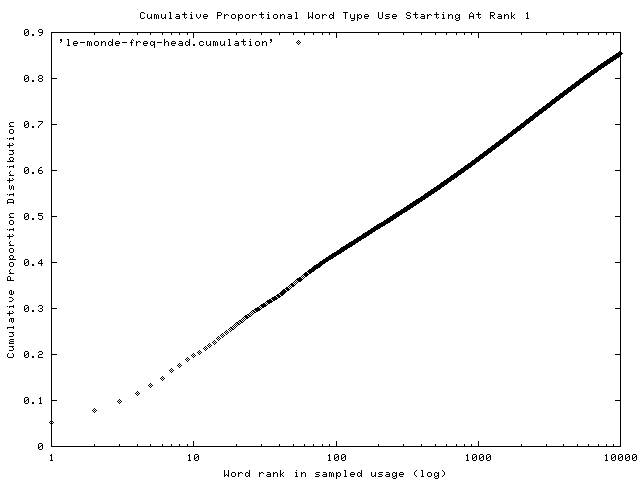
The model underlying the LEX measure is based on a well-known mathematical distribution, illustrated in Figure A, describing the pattern of word choice in a full year’s (1995) text of the Paris newspaper Le Monde. That file contained over 44 million tokens. The X axis describes the use journalists made of the most common French type (‘de’), and every other French word-type through rank 10,000. Each word’s rank is represented by its log. Le Monde’s second, third, fourth and fifth most common types were ‘le’,’la’, ‘les’ and ‘et’. The Y axis represents the cumulative proportion of all words in those texts, at each rank. The first five French types account alone for ~14 percent of all tokens -- one in every seven words used in Le Monde. Combined, the first 10,000 most common French word-types accounted for ~85 percent. The model behind LEX asserts that type ranking remains essentially stable across centuries and is robust across most Western languages. Grammatical terms will dominate through approximately ranks 75-100 and their ranks will be highly correlated across languages (once provision is made for gender and singular/plural forms and special orthographic forms). When French gender and the singular/plural forms are combined, ‘la’, ‘le’, ‘les’ and ‘l’xxx make ‘the’ the most common term in French. The combined ‘de’ and ‘des’ rank second, with ’et’ third–- the same order as in English.
FIGURE A. Pattern of word choice in Le Monde
Empirically, word use distributions closely approximate this model’s linear (lognormal) pattern of word choice. Thorndike and Lorge’s (1944) usage estimates of 30,000 English types coincided well with estimates in the 5 million word corpus by Carroll, Davies and Richman (1971). The fit is also tight between this model and actual word choice in 22 international newspapers in 2003 (this time, only 42,246 tokens). FIGURE B. These samples came from English-language newspapers published in Latin America, the Middle East, Africa, the Far East, the Indian sub-continent, Europe, Russia and North America. Twelve sub-samples were taken from each paper: six were drawn at random, the remaining six were taken from the first page, the editorial page, a sport page, local news, entertainment, and from the business/financial section. Independent analyses of newspapers since 1665 show that the fit between newspapers and this linear model has been tight since 1665–LEX is both precise and stable: suitable for old, new and future texts.
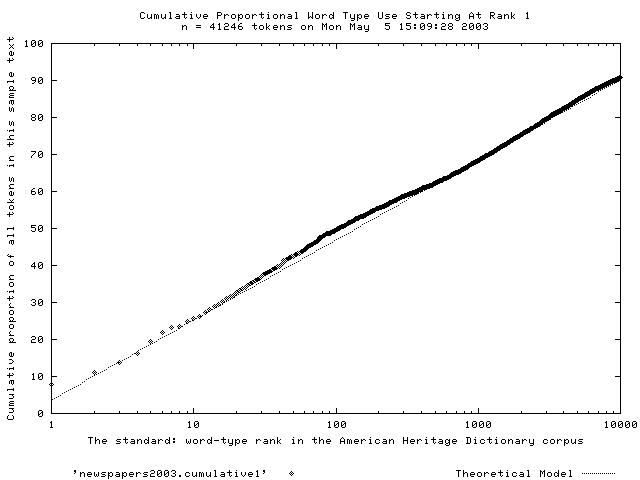
FIGURE B. Pattern of word choice in 22 newspapers–2003.
FIGURE C describes texts located near LEX’s empirical limits: (a) the texts from post-WW II 1st grade basal readers, (b) independent newspaper samples from 60 English-language newspapers published around the world from 1665 to 1995, (c) and abstracts of scientific reports in Nature.
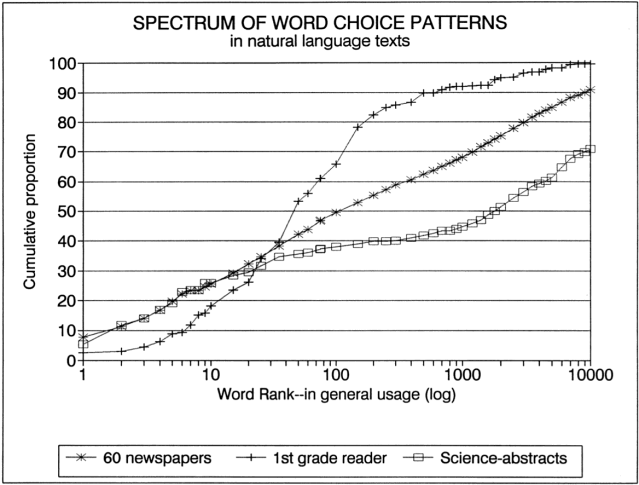
FIGURE C The range of LEX variation in natural texts
One implication of Figures B and C is that the software used to estimate a text’s ‘accessibility’ may be more widely applicable than English. If a ‘dictionary’ of the first 10,000 most common types were developed (along the lines of the Le Monde analysis), providing estimates of relative frequency of usage per million tokens of each type, then that file may be substituted into the Qanalysis software, replacing its English dictionary and relative frequencies of occurrence statistics–that would provide a ranking of French types. Whether an equally valid French LEX would be created, remains to be seen.
A spectrum of LEX scores in natural texts.
TABLE 1 described the spectrum of natural texts. A mother’s speech to her own child, at home alone, is typically in the -46 LEX range. Reports of original research in the two weekly science journals Nature and Science are now in the +35 range. Since 1665, English-language newspapers published throughout the world have had LEX scores at or near 0.0. That makes newspapers a convenient reference for interpreting the lexical difficulty of any text. [As would be expected, the several sections within a newspaper differ in their LEX: sports sections typically have modest negative LEX scores, editorial business/financial, and science sections typically have modest + LEX scores].
The concept of ‘lexical accessibility’.
Since the first decade of the 20th century, access to lexical entries has been known to be strongly frequency-dependent--to recognize or retrieve a term from memory is time-dependent. This relation was the grounds for designing ‘word knowledge’ and ‘vocabulary’ tests--the best-validated of all psychometric tests--now used in nearly all societies, cultures, and languages to estimate a major component of verbal aptitude. To dismiss these tests as mere ‘vocabulary’ texts misses their power: ‘words’ are the keys to our consensual understanding of underlying referents for concepts, the domains to which those concepts apply, and relationships between those concepts and
domains. Word knowledge is a window to a child’s conceptual and knowledge base.
THE CONTENTS OF CORNELL CORPUS 2000.
1. This corpus contains 5000+ natural texts selected to represent the three principal forms of natural texts: Print, Speech and Broadcast. All texts are ASCII files and downloadable. In most cases, they are approximately 1000-token stratified samples.
2. A table -- SUMMARY STATISTICS-- supplies LEX estimates for each of 55 natural text categories into which those 5000+ texts are sorted. This File is named: CUCORPUS2K
3. Version 6 of QANALYSIS--the lexical analysis program.
This program can be used now -- its calculations are known to coincide with those made by the five earlier versions, but QANALYSIS is not a polished program, yet. It is not a commercial product but a research tool, whose development is driven by the research program. It is more refined and detailed than its predecessors but it needs further testing, to be made more user-friendly, its many files must be transferred to spreadsheets more easily, its graphs (akin to Figures A, B and C) need further work, goodness-of-fit measures need improvement, and departures in actual word usage from the linear model should be made more specific and their location highlighted.
4. EDITING TEXTS.
LEXGUIDE2003.TXT. This is a most important FILE. It provides the editing rules for making every text and its LEX measurements comparable. Editing is the downside to using LEX. To reduce editing effort, an elaborated Search and Replace File (named REPLACE2) can be used to automate much of the necessary editing, but texts must still be examined to make certain the text complies with LEX editing rules. Otherwise one cannot compare texts or interpret their meaning which is based on the 5000+ texts in the Cornell Corpus, all of which comply with LER editing rules.
5. SUBSTANTIVE AND VALIDATION RESEARCH.
A. The Growing Inaccessibility of Science. D. P. Hayes, Nature, Vol. 356, 30 April, 1992, pp 739-740. This paper served two purposes: (1) evidence is produced showing that at the end of WW II, Nature (and Science, later) relaxed their accessibility standards. From their inceptions in the mid- to late-1800s until the end of WW II, researchers were obliged to write at the level of a newspaper in these journals. After WW II, they were permitted to write at more demanding (technical)professional levels. The su+bsequent rise in LEX levels reduced the layperson’s and scientists’ access to what was going on throughout the sciences; (2) this paper provided a large-scale validation test of LEX’s ability to track changes in each discipline’s principal professional journals, as well as in science and technology magazines.
B. SCHOOLBOOK SIMPLIFICATION (American Educational Research Journal, Summer,1996 No. 2, pp 489-508, Donald P. Hayes, L.T. Wolfer and M. F. Wolfe) described changes in the LEX levels of American and British schoolbooks used in pre-primary through college level courses. The analyses showed the extent of simplification in every grade, from primers on. Simplification of schoolbooks had occurred after the American Civil War and again after WW I. The post WW II simplification began in the late 1940s and continued through the 1950s–reducing student access to the depth or breadth of domain knowledge. Substantively, this paper links the nationwide use of simplified texts to the huge decline in mean verbal SAT and ACT scores which began in 1963 and continued declining in each of the next 16 years. In the quarter-century since, schools have tried many means to raise verbal scores, but SAT and NEAP testing fails to find any increase -- whereas mathematics scores have risen modestly. The one thing publishers and educators have not done is raise modern textbook LEX to its former level in every grade.
C. 5th Intl. Conference on Social Science Methodology, Univ. of Koln, Cologne, Germany, Oct. 3-6, 2000. This paper described LEX and some of the experimental and comparative validation studies. One study tracked the systematic decline in LEX scores for President Nixon and a dozen of his principal advisors while conversing about Watergate-related matters in the Oval Office over an eight month period. The baseline LEX levels for each man serves to measure the extent of the change in
these dozen men’s unrehearsed speech. The steady decline in their LEX scores are interpreted as reflecting as a stress effect: the prospect of their being prosecuted for felonies–and loss of their jobs. As news reached them of the Special Prosecutor’s (and others’) progress in tracking responsibility for ‘dirty tricks’, the break-in, the illegal dispersing of campaign funds, and the ‘plumbers’ activities, these men’s LEX scores became more and more skewed toward common words. The distraction effect of stress may have made their texts rely more on the most accessible words in their personal lexicons.
D. Motherese: lexical choice by mothers talking with child.
Donald P. Hayes and Margaret G. Ahrens. Journal Of Child
Language, Vocabulary simplification for children.Vol 15 1988),
pp. 395–410]. This paper challenges the widespread assumption that mothers raise their own LEX levels while speaking with their child during the period when a child is becoming a speaker of
a language(between 18 months and 60 months of age). Presumably, this is done to facilitate the children’s language development. This was a longitudinal study of 32 mothers and their children (the data are from a study designed and executed by G. Wells, 1981). No such lexical accommodation by mothers for their children was found. The children’s speech converged on adult speech patterns without this hypothetical guidance from their mothers. Spontaneous adult-to-adult talk is more demanding than adult-to-child talk, but not by much (LEX = -37.5 and -45.8).
6. A representative sample of 101 texts drawn from the
CORNELL CORPUS is contained in UNIVSA~1.WPD (readable by any PC word processor). This table not only supplies LEX values for specific texts but the correlation matrix for the principal statistics for those 101 text samples as well.
7. A Commentary by Jonathan Knight in Nature, March 22, 2003.
Knight’s article discusses LEX and the implications for science’s growing inaccessibility to scientists, much less the public.
TECHNICAL DETAILS: – written by Marty White, who wrote QANALYSIS.
http://www.soc.cornell.edu/hayes-lexical-analysis/qanalyze/
The programs are in Perl, which, while not an ideal programming language for
academics, is an ideal language for text processing. The program is split into
several parts, plus several data files.
`qanalyze` is the interactive front-end. Type `perl qanalyze` to get help on
how to use it. This program uses a text viewer of your choice, and uses
gnuplot to display graphs of analysis results.
`plex` is a program that automatically marks-up an ASCII text in the mark-up
notation developed by Professor Hayes for use in his earlier programs. Such
mark-up must be at least partly done by a human for proper scientific results,
but the plex program can do the better half of the work by using a few simple
rules-of-thumb (for instance, any word consisting of two or more capital
letters is probably an acronym and therefore a proper noun and should be marked
"illegitimate" for the purposes of analysis).
`qx` does the statistical analysis of the given text and generates report
files.
The data files consist of a common-word lexicon, containing the 10,000 most
commonly used words and their associated U-values (usage per million), and one
or more ordinary spell-checking files listing as many legitimate words as can
be had. The common-word lexicon is used for statistical analysis, while the
spell-checking words are used simply to decide whether a given sequence of
letters is a word or not. Words in the spell-checking file that are
capitalized are assumed to be proper names and this is used by plex to help
decide which words are or are not proper names.
qanalyze is Copyright (C) 2001 Marty White
This program is free software; you can redistribute it and/or
modify it under the terms of the GNU General Public License
as published by the Free Software Foundation; either version 2
of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program; if not, write to the Free Software
Foundation, Inc., 59 Temple Place - Suite 330, Boston, MA 02111-1307, USA.
Marty White
http://www.soc.cornell.edu/computing/
mailto:lmw22@cornell.edu
305 Uris Hall, Cornell University